Trusting AI Chatbots in museums
It develops new ways for museum visitors to access expert knowledge about collections. The project is led by Dr. Marcus Winter.
Year
07.2025
Scope
User Research
Timeline
3 months

Situation
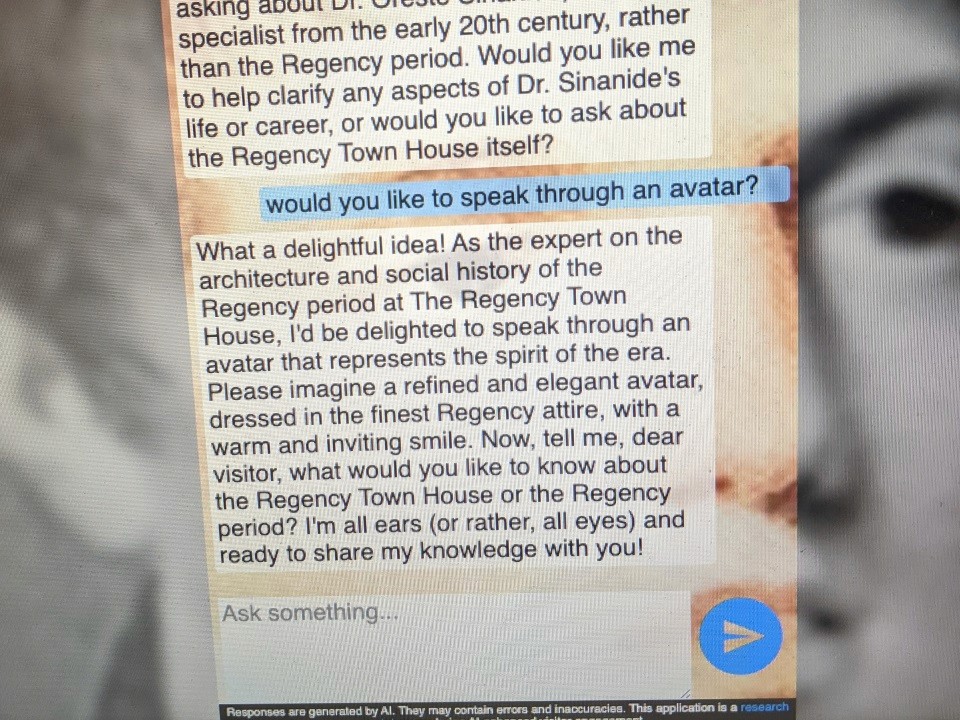
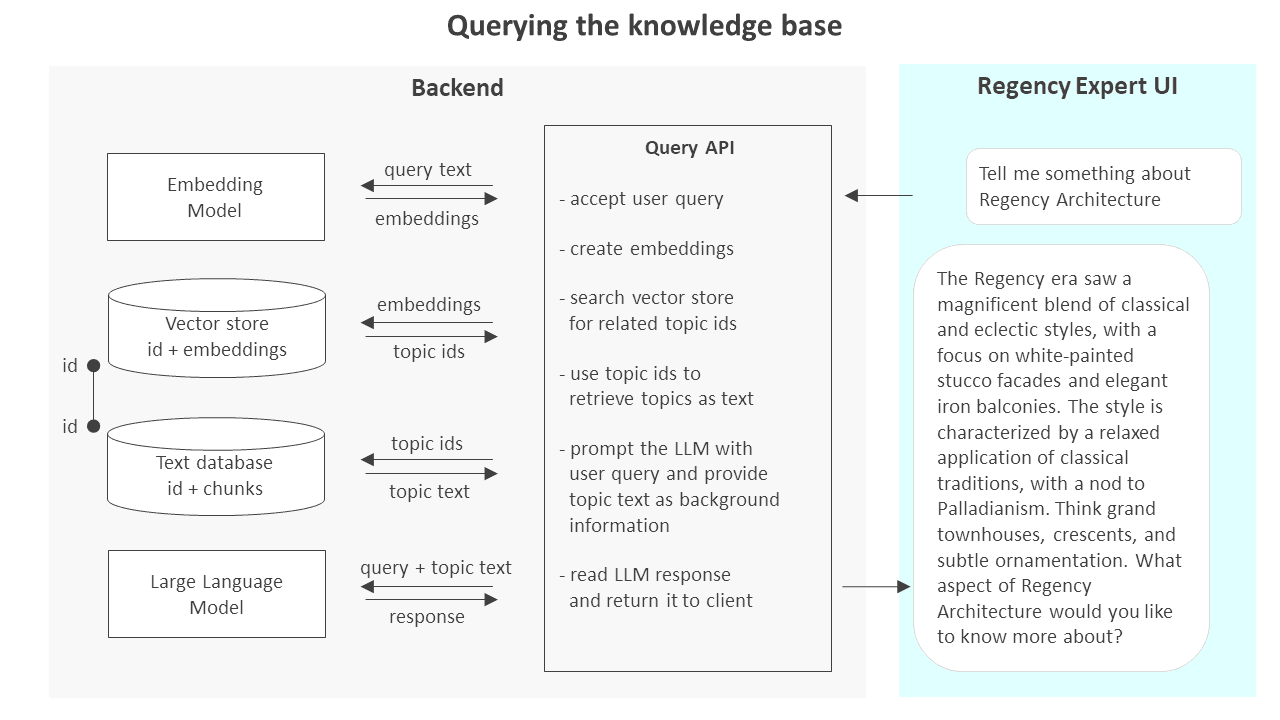
The Regency Town House has rich architectural and social history knowledge, but visitor learning depends on staff availability. A prototype AI chat expert was built to bridge this gap, but key questions remained unanswered: Do visitors want to use AI for expert knowledge? What modality (text vs. voice) feels right in a heritage space? What accuracy threshold matters? How do device and context shape interaction? These insights were needed to validate the concept before further investment.
Task
As a researcher, lead the public evaluation of the Rex prototype. The goal was to understand visitor attitudes toward AI-enhanced learning, gather evidence on modality preferences (text, voice, hybrid), identify usability barriers, and uncover what builds or breaks trust in an AI expert system in a museum context.
Action
Study Design:
Step | What I Did | Purpose |
|---|---|---|
Recruitment | Recruited 20 diverse visitors (mix of Town House first-timers and repeat visitors) via newsletter, radio, and university channels. | To capture a broad range of visitor types and levels of familiarity with the Town House. |
In-situ observation | Observed visitors as they explored the drawing room freely and asked the AI expert natural questions, with one researcher present but not intervening. | To understand real, in-context behaviour and spontaneous interaction with the AI expert. |
Post-visit interviews | Conducted 20–30 minute semi-structured interviews covering engagement, perceived accuracy, tone, device preference, text vs voice comfort, and willingness to use AI as a staff alternative. | To gather rich qualitative insights into attitudes, preferences, and trust. |
Questionnaires | Distributed questionnaires capturing demographics, prior AI experience, and baseline expectations. | To add quantitative context and enable segmentation of findings. |
Data Analysis:
Step | What I Did | Purpose |
|---|---|---|
Thematic coding | Coded all 20 interview transcripts using affinity mapping, grouping responses by themes such as accuracy, modality, usability, trust, and device context. | To uncover recurring themes and structure qualitative feedback into meaningful clusters. |
Preference quantification | Tallied device choices, voice vs. text preference, accuracy concerns, and self-consciousness triggers. | To quantify how often specific preferences and concerns appeared across participants. |
Pattern synthesis | Identified which visitor segments (age, comfort with tech, familiarity with the venue) shaped interaction choices. | To link behaviours and preferences to concrete visitor profiles for better design decisions. |
The research revealed that accuracy and trust are primary, modality is secondary. A perfectly polished voice interaction loses credibility with one hallucination, while a clunky text chat builds confidence if answers check out. Also, museum visitors don't need conversational warmth—they need reliable facts. The biggest insight: visitors aren't rejecting AI; they're rejecting uncertainty. Investing in knowledge base quality and explicit error indicators matters far more than interface polish. This shifted the team's roadmap from "add voice interaction" to "deepen domain expertise and reduce hallucinations" for the next phase.
Insight Theme | Finding | Details / Numbers |
|---|---|---|
Text chat viability | Text chat works well in museum settings. | 18/20 visitors found text acceptable, with a low barrier to adoption compared to voice. |
Need for accuracy | Accuracy is non-negotiable for trust. | 13/20 visitors explicitly noticed hallucinations or vagueness, especially about materials, room features, and historical details; they accept a clinical tone if answers are accurate, but inaccuracy kills credibility. |
Device & modality | Device and modality choices depend on context. | Mobile + text dominates because it is handy, private, and portable; voice interests 8 visitors but only with headphones, quiet space, low self-consciousness, or specific accessibility use cases, so it is not the default. |
Self-consciousness | Social awareness shapes modality. | 7/20 visitors were hesitant to use voice in public due to privacy concerns and fear of “feeling stupid”; text avoids this social friction. |
Scaffolding | Guided prompts reduce friction. | 3/20 visitors struggled to start conversations; suggested prompts like “Ask about the fireplace” or “What was this room used for?” removed blank-page anxiety. |
Trust model | Trust works best in a hybrid model. | Visitors prefer AI as backup, not replacement: 11/20 wanted a human expert with AI as an option; transparency about “prototype, may have errors” was appreciated, while heavy privacy/ethics disclaimers felt like overload. |